
Machine-Learning-Based Method for Finding Optimal Video-Codec Configurations Using Physical Input-Video Features
R. Kazantsev, S. Zvezdakov, and D. Vatolin
Contact us:
- roman.kazantsev@graphics.cs.msu.ru
- sergey.zvezdakov@graphics.cs.msu.ru
- dmitriy.vatolin@graphics.cs.msu.ru
- video@compression.ru
Abstract
Modern video codecs have many compression-tuning parameters from which numerous configurations (presets) can be constructed. The large number of presets complicates the search for one that delivers optimal encoding time, quality, and compressed-video size. This paper presents a machine-learning-based method that helps to solve this problem. We applied the method to the x264 video codec: it searches for optimal presets that demonstrate 9-20% bitrate savings relative to standard x264 presets with comparable compressed-video quality and encoding time. Our method is faster upto 10 times than existing solutions.
Key Features
- Proposed machine-learning-based method is capable of finding the preset that
- provides 9-20% bitrate savings against x264 standard presets
- is faster than other existing solutions by 10 times
- Developed dataset contains more than 350 videos and 1300 presets of x264 codec
- 13 video physical features are compared during the research
- Lap Blur (acutance metric) and TI ME (temporal complexity) are the most relevant
Dataset
The following were computed for each video-preset pair:
- encoding time
- objective quality metric — SSIM
- a size of bitstream resulted by encoding
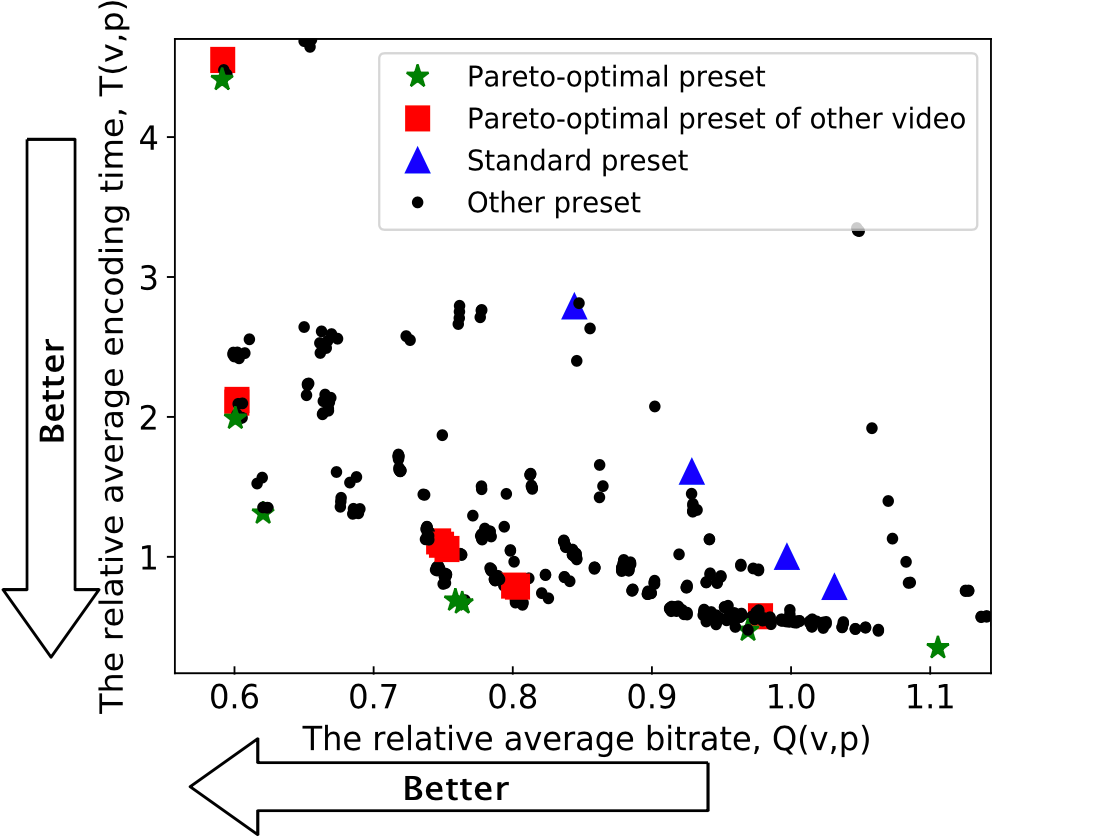
The scatter plot below demonstrates inefficiency of standard presets and Pareto-optimal presets for a different video.
Proposed method
- Training
- Cluster videos according to similarity of Pareto-frontier structures. Four clusters were obtained
- Assign to each cluster the Pareto-optimal set of some video from this cluster
- Train a model that predicts a cluster using the physical video features
- Inference
- Compute the physical features for input video
- Predict a cluster using the model and output Pareto- optimal set assigned to the predicted cluster
Results
The chart below shows the importance of physical video features in trained model.
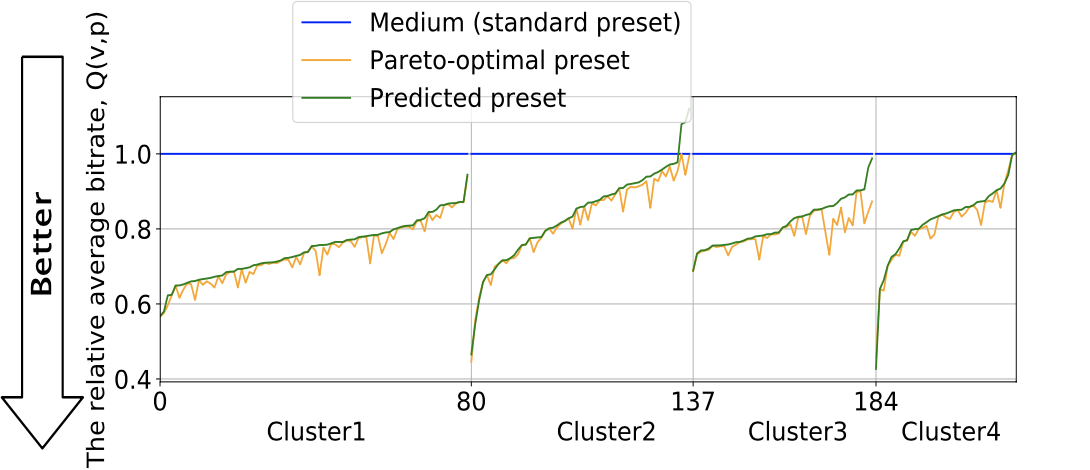
Below you can see average bitrates delivered using optimal, predicted, and standard presets over all train videos in each cluster.
Comparison
Below the average bitrate savings [%] of the predicted presets versus standard presets are proposed, as well as execution time obtained using different methods.
| Sequence | Faster | Fast | Medium | Slow | Slower | Veryslow | Placebo | Time,sec |
|---|---|---|---|---|---|---|---|---|
| NSGA-II | 15.9 | 30.2 | 29.7 | 34.9 | 32.2 | 29.0 | 28.3 | 13684.4 |
| Popov’s | 8.0 | 29.0 | 28.4 | 34.9 | 32.2 | 28.3 | 29.0 | 10039.7 |
| Zvezdakov’s | 11.0 | 30.2 | 29.8 | 34.9 | 32.2 | 28.7 | 29.4 | 7705.2 |
| Ours | 15.8 | 21.3 | 21.8 | 27.7 | 24.9 | 9.7 | 10.5 | 735.5 |
The second table shows bitrate savings [%] obtained using the predicted presets versus the standard presets on JVET videos.
| Sequence | Faster | Fast | Medium | Slow | Slower | Veryslow | Placebo |
|---|---|---|---|---|---|---|---|
| Cactus | 6.0 | 16.5 | 17.5 | 15.0 | 13.3 | 8.0 | 15.7 |
| DugsAndLegs | 17.2 | 27.9 | 26.5 | 21.0 | 15.4 | 1.3 | 11.5 |
| KristenAndSara | 4.5 | 12.3 | 16.0 | 24.7 | 25.1 | 0.0 | 9.0 |
| ParkScene | 12.6 | 17.5 | 29.0 | 22.8 | 19.0 | 14.1 | 16.3 |
| PeopleOnStreet | 16.8 | 21.9 | 27.6 | 33.7 | 31.4 | 20.2 | 29.8 |
| Average | 11.4 | 19.2 | 23.3 | 23.4 | 20.8 | 8.7 | 16.4 |
Cite us
@inproceedings{inproceedings,
author = {Kazantsev, Roman and Zvezdakov, Sergey and Vatolin, Dmitriy},
year = {2020},
month = {03},
pages = {374-374},
title = {Machine-Learning-Based Method for Finding Optimal Video-Codec Configurations Using Physical Input-Video Features},
doi = {10.1109/DCC47342.2020.00079}
}Contact us
For questions and propositions, please contact us: roman.kazantsev@graphics.cs.msu.ru, sergey.zvezdakov@graphics.cs.msu.ru, dmitriy.vatolin@graphics.cs.msu.ru, and video@compression.ru
See also
- Machine-Learning-Based Method for Content-Adaptive Video Encoding
- Power Consumption of Video-Decoders on Various Android Devices
- Video-Decoder Power Consumption on Android Devices: Power-Estimation Method, Dataset Creation, and Analysis Results
- MSU Mobile Video Codecs Benchmark
- Our other benchmarks
References
1) V. Popov, “Automatic method of choosing pareto optimal video codec’s parameters,” M.S. thesis, Lomonosov Moscow State University, 2009.
2) K. Deb, A. Pratap, S. Agarwal, and T. Meyarivan, “A fast and elitist multiobjective genetic algorithm: NSGA-II,” IEEE Transactions on Evolutionary Computation, vol.6, no. 2, pp. 182–197, August 2002.
3) S. Zvezdakov and D. Vatolin, “Building a x264 video codec model,” in Innovative technologies in cinema and education: IV International Symposium, Moscow, Russia, 2017, pp. 56–65, VGIK Moscow.
4) Telecommunication Standardization Sector of ITU, “Subjective video quality assessment methods for multimedia applications,” in Series P. Telephone Transmission Quality, Telephone Installations, Local Line Networks, pp. 4–6. April 2008.
5) K. Simonyan, S. Grishin, D. Vatolin, and D. Popov, “Fast video super-resolution via classification,” in Proceedings of 15th IEEE International Conference on Image Processing, San Diego, CA, USA, October 2008, pp. 349–352.
6) F. Crete-Roffet, T. Dolmiere, P. Ladret, and M. Nicolas., “The blur effect: Perception and estimation with a new no-reference perceptual blur metric,” in SPIE Electronic Imaging Symposium Conf Human Vision and Electronic Imaging, San Jose, CA, USA, January 2007, pp. 6492–6516.
7) R. Bansal, G. Raj, and T. Choudhury, “Blur image detection using laplacian operator and opencv,” in Proceedings of the SMART-2016, Moradabad, India, November 2016.
8) N. Lakshmi, Y. Latha, A. Damodharam, and K. Prasanna, “Implementation of content based video classification using hidden markov model,” in Proceedings of 7th International Advance Computing Conference (IACC), Hyderabad, India, January 2017.